In late 2016, Gartner predicted that 30 p.c of internet looking classes can be completed with out a display by 2020. Earlier the identical 12 months, Comscore had predicted that half of all searches can be voice searches by 2020. Although there’s latest proof to recommend that the 2020 image could also be extra sophisticated than these broad-strokes projections indicate, we’re already seeing the affect that voice search, synthetic intelligence, and sensible software program brokers like Alexa and Google Assistant are making on the best way data is discovered and consumed on the internet.
Article Continues Beneath
Along with the indexing perform that conventional engines like google carry out, sensible brokers and AI-powered search algorithms are actually bringing into the mainstream two extra modes of accessing data: aggregation and inference. Consequently, design efforts that concentrate on creating visually efficient pages are not enough to make sure the integrity or accuracy of content material printed on the internet. Relatively, by specializing in offering entry to data in a structured, systematic means that’s legible to each people and machines, content material publishers can be sure that their content material is each accessible and correct in these new contexts, whether or not or not they’re producing chatbots or tapping into AI straight. On this article, we’ll take a look at the kinds and affect of structured content material, and we’ll shut with a set of sources that may assist you get began with a structured content material strategy to data design.
The position of structured content material#section2
Of their latest guide, Designing Related Content material, Carrie Hane and Mike Atherton outline structured content material as content material that’s “deliberate, developed, and linked exterior an interface in order that it’s prepared for any interface.” A structured content material design strategy frames content material sources—like articles, recipes, product descriptions, how-tos, profiles, and many others.—not as pages to be discovered and skim, however as packages composed of small chunks of content material knowledge that every one relate to at least one one other in significant methods.
In a structured content material design course of, the relationships between content material chunks are explicitly outlined and described. This makes each the content material chunks and the relationships between them legible to algorithms. Algorithms can then interpret a content material package deal because the “web page” I’m searching for—or remix and adapt that very same content material to provide me a listing of directions, the variety of stars on a assessment, the period of time left till an workplace closes, and any variety of different concise solutions to particular questions.
Structured content material is already a mainstay of many forms of data on the internet. Recipe listings, as an illustration, have been based mostly on structured content material for years. After I search, for instance, “bouillabaisse recipe” on Google, I’m supplied with an ordinary checklist of hyperlinks to recipes, in addition to an outline of recipe steps, a picture, and a set of tags describing one instance recipe:
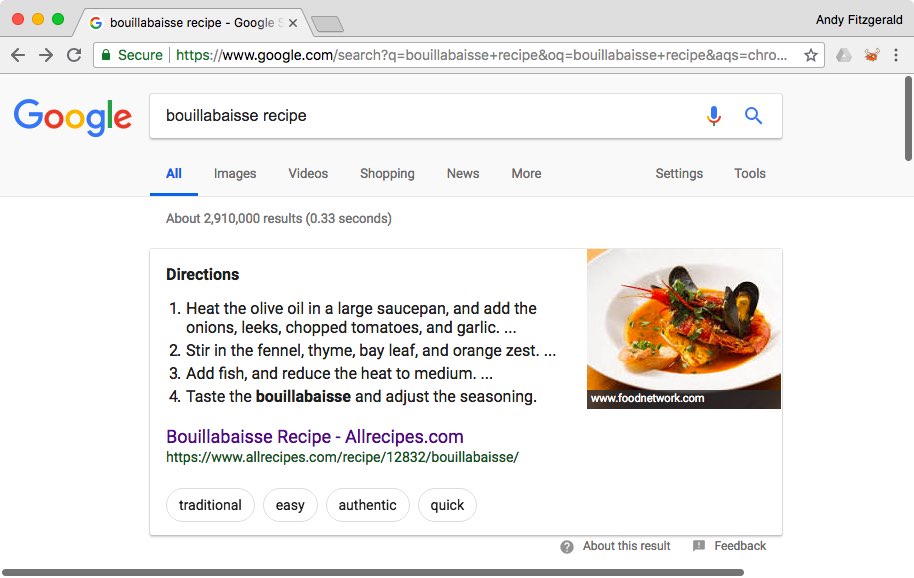
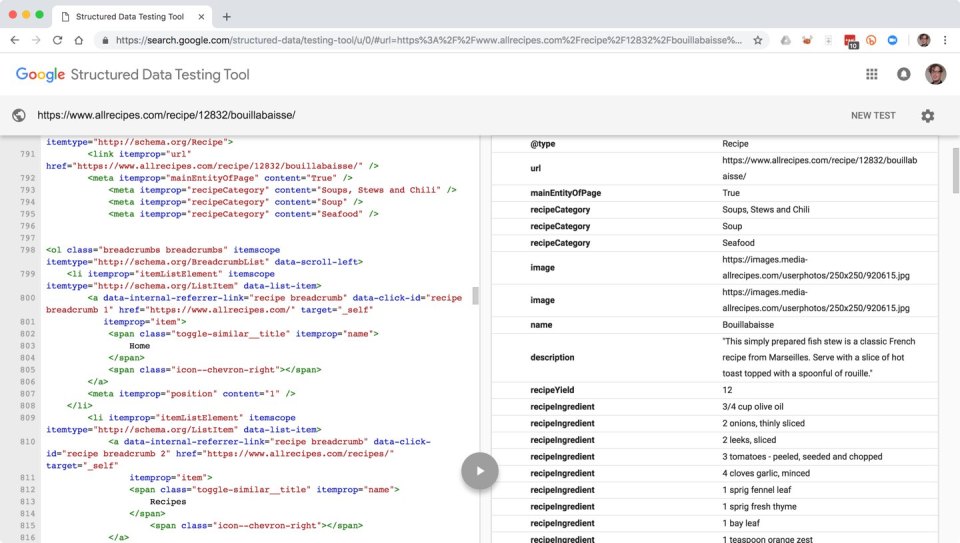
This “featured snippet” view is feasible as a result of the content material writer, allrecipes.com, has damaged this recipe into the smallest significant chunks applicable for this material and viewers, after which expressed details about these chunks and the relationships between them in a machine-readable means. On this instance, allrecipes.com has used each semantic HTML and linked knowledge to make this content material not merely a web page, but in addition legible, accessible knowledge that may be precisely interpreted, tailored, and remixed by algorithms and sensible brokers. Let’s take a look at every of those components in flip to see how they work collectively throughout indexing, aggregation, and inference contexts.
Software program agent search and semantic HTML#section3
Semantic HTML is markup that communicates details about the significant relationships between doc components, versus merely describing how they need to look on display. Semantic components similar to heading tags and checklist tags, as an illustration, point out that the textual content they enclose is a heading (<h1>) for the set of checklist objects (<li>) within the ordered checklist (<ol>) that follows.
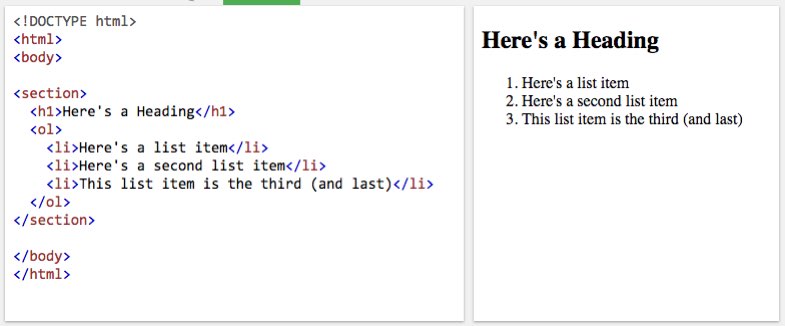
HTML structured on this means is each presentational and semantic as a result of individuals know what headings and lists appear to be and imply, and algorithms can acknowledge them as components with outlined, interpretable relationships.
HTML markup that focuses solely on the presentational features of a “web page” could look completely high-quality to a human reader however be utterly illegible to an algorithm. Take, for instance, the Metropolis of Boston web site, redesigned a couple of years in the past in collaboration with top-tier design and growth companions. If I need to discover details about find out how to pay a parking ticket, a hyperlink from the house web page takes me on to the “ Pay a Parking Ticket” display (scrolled to indicate element):
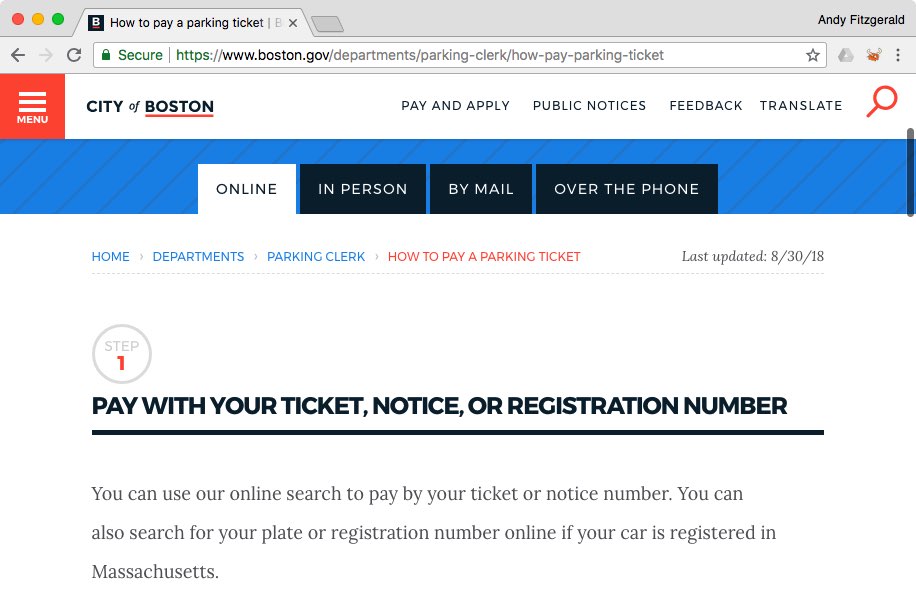
As a human studying this web page, I simply perceive what my choices are for paying: I will pay on-line, in individual, by mail, or over the cellphone. If I ask Google Assistant find out how to pay a parking ticket in Boston, nonetheless, issues get a bit complicated:
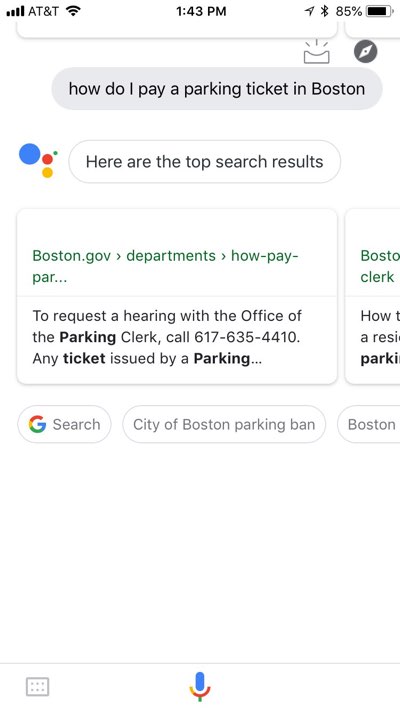
Not one of the hyperlinks supplied within the Google Assistant outcomes take me on to the “ Pay a Parking Ticket” web page, nor do the descriptions clearly let me know I’m heading in the right direction. (I didn’t ask about requesting a listening to.) It’s because the content material on the Metropolis of Boston parking ticket web page is styled to speak content material relationships visually to human readers however just isn’t structured semantically in a means that additionally communicates these relationships to inquisitive algorithms.
The Metropolis of Seattle’s “Pay My Ticket” web page, although it lacks the polished visible type of Boston’s website, additionally communicates parking ticket fee choices clearly to human guests:
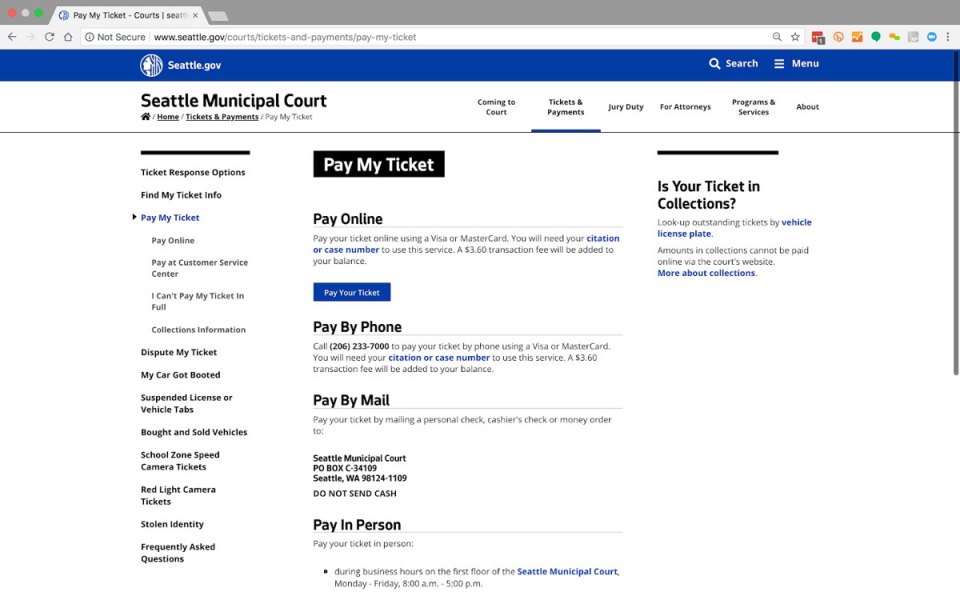
The equal Google Assistant search, nonetheless, gives a way more useful end result than we see with Boston. On this case, the Google Assistant end result hyperlinks on to the “Pay My Ticket” web page and likewise lists a number of methods I will pay my ticket: on-line, by mail, and in individual.
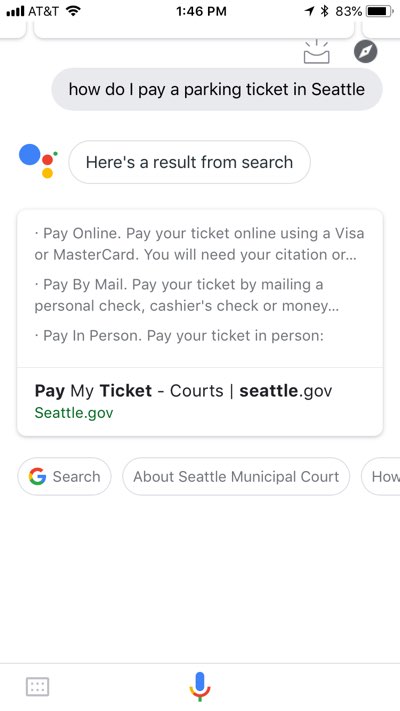
Regardless of the visible simplicity of the Metropolis of Seattle parking ticket web page, it extra successfully ensures the integrity of its content material throughout contexts as a result of it’s composed of structured content material that’s marked up semantically. “Pay My Ticket” is a level-one heading (<h1>), and every of the choices beneath it are level-two headings (<h2>), which point out that they’re subordinate to the level-one component.
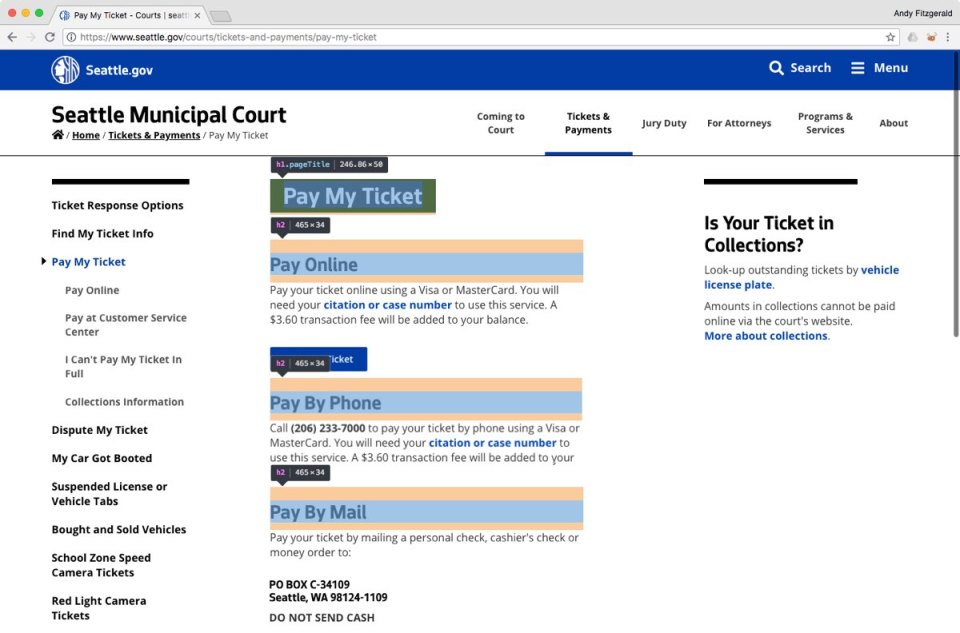
These components, when designed properly, talk data hierarchy and relationships visually to readers, and semantically to algorithms. This construction permits Google Assistant to fairly surmise that the textual content in these <h2> headings represents fee choices below the <h1> heading “Pay My Ticket.”
Whereas this use of semantic HTML gives distinct benefits over the “web page show” styling we noticed on the Metropolis of Boston’s website, the Seattle web page additionally exhibits a weak spot that’s typical of guide approaches to semantic HTML. You’ll discover that, within the Google Assistant outcomes, the “Pay by Telephone” possibility we noticed on the internet web page was not listed. If we take a look at the markup of this web page, we are able to see that whereas the three choices discovered by Google Assistant are wrapped in each <robust> and <h2> tags, “Pay by Telephone” is simply marked up with an <h2>. This irregularity in semantic construction could also be what’s inflicting Google Assistant to omit this selection from its outcomes.
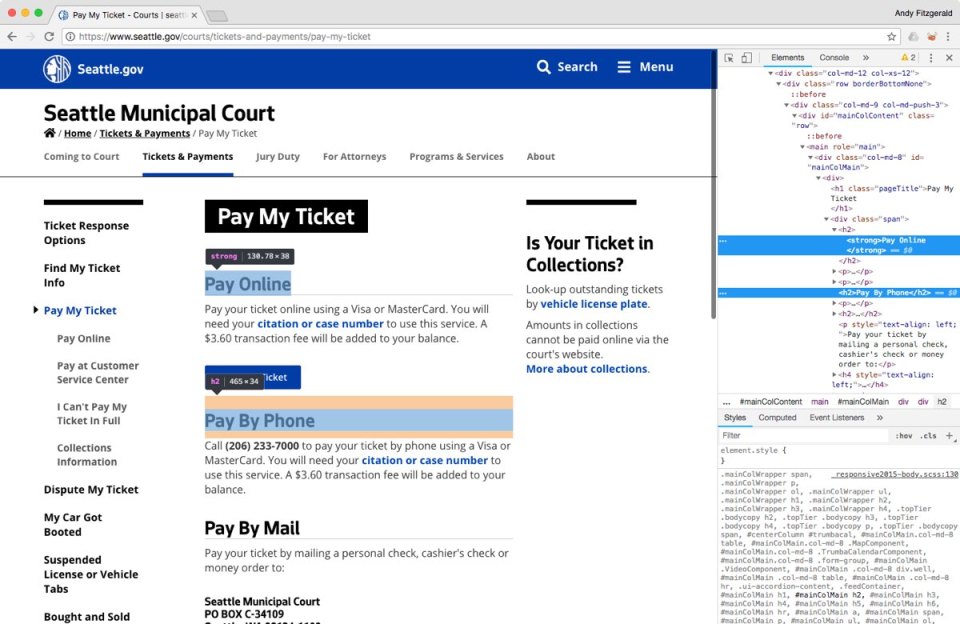
Though every of those components would look the identical to a sighted human creating this web page, the machine deciphering it reads a distinction. Whereas WYSIWYG textual content entry fields can theoretically help semantic HTML, in observe all of them too usually fall prey to the idiosyncrasies of even essentially the most well-intentioned content material authors. By making significant content material construction a core component of a website’s content material administration system, organizations can create semantically right HTML for each component, each time. That is additionally the muse that makes it attainable to capitalize on the wealthy relationship descriptions afforded by linked knowledge.
Linked knowledge and content material aggregation#section4
Along with discovering and excerpting data, similar to recipe steps or parking ticket fee choices, search and software program agent algorithms additionally now combination content material from a number of sources through the use of linked knowledge.
In its most simple kind, linked knowledge is “a set of finest practices for connecting structured knowledge on the internet.” Linked knowledge extends the fundamental capabilities of semantic HTML by describing not solely what sort of factor a web page component is (“Pay My Ticket” is an <h1>), but in addition the real-world idea that factor represents: this <h1> represents a “pay motion,” which inherits the structural traits of “commerce actions” (the alternate of products and companies for cash) and “actions” (actions carried out by an agent upon an object). Linked knowledge creates a richer, extra nuanced description of the connection between web page components, and it offers the structural and conceptual data that algorithms must meaningfully carry knowledge collectively from disparate sources.
Say, for instance, that I need to collect extra details about two suggestions I’ve been given for orthopedic surgeons. A seek for a primary advice, Scott Ruhlman, MD, brings up a set of hyperlinks in addition to a Information Graph information field containing a photograph, location, hours, cellphone quantity, and critiques from the net.
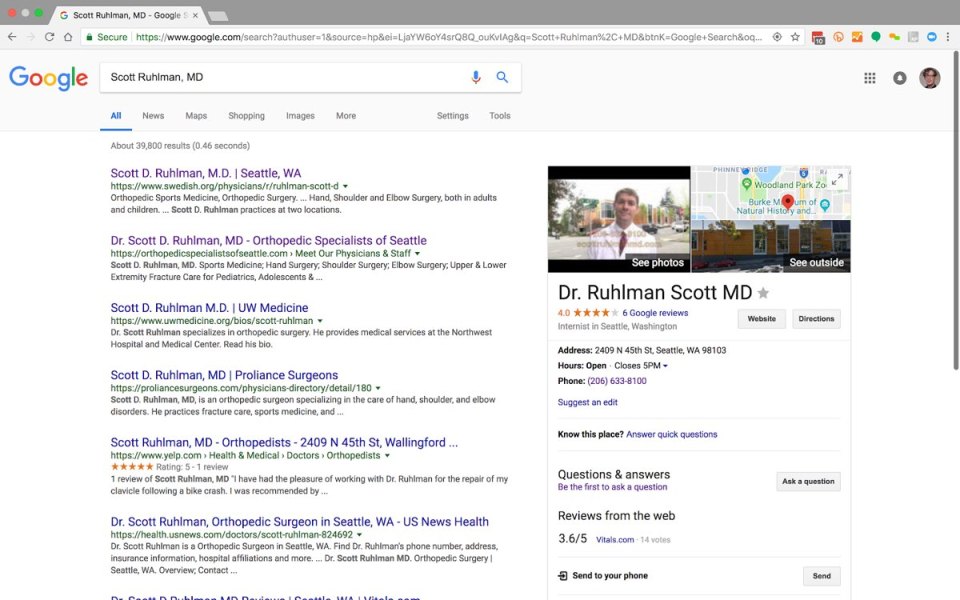
If we run Dr. Ruhlman’s Swedish Hospital profile web page by way of Google’s Structured Knowledge Testing Software, we are able to see that content material about him is structured as small, discrete components, every of which is marked up with descriptive sorts and attributes that talk each the that means of these attributes’ values and the best way they match collectively as an entire—all in a machine-readable format.
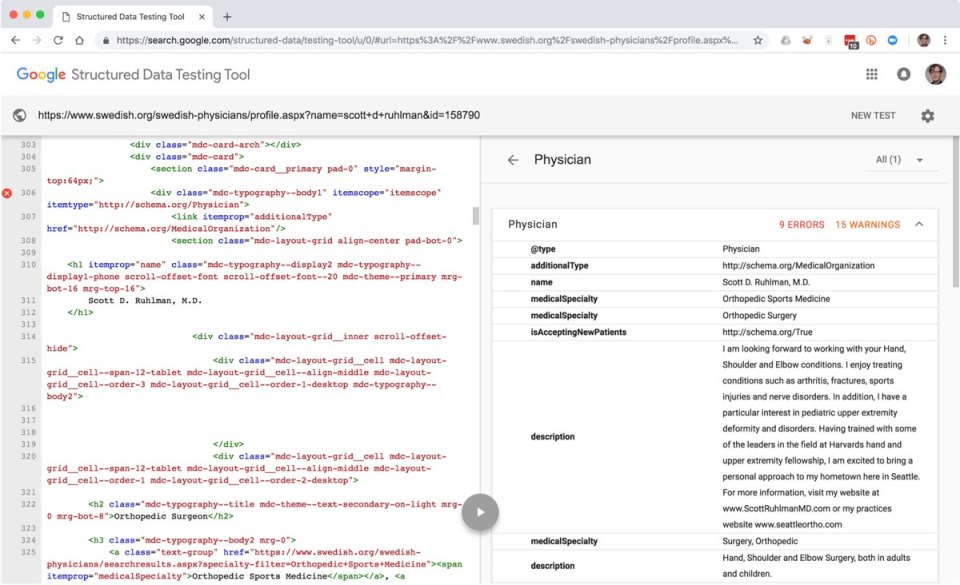
On this instance, Dr. Ruhlman’s profile is marked up with microdata based mostly on the schema.org vocabulary. Schema.org is a collaborative effort backed by Google, Yahoo, Bing, and Yandex that goals to create a standard language for digital sources on the internet. This structured content material basis offers the semantic base on which extra content material relationships may be constructed. The Information Graph information field, as an illustration, contains Google critiques, which aren’t a part of Dr. Ruhlman’s profile, however which have been aggregated into this overview. The overview additionally contains an interactive map, made attainable as a result of Dr. Ruhlman’s workplace location is machine-readable.
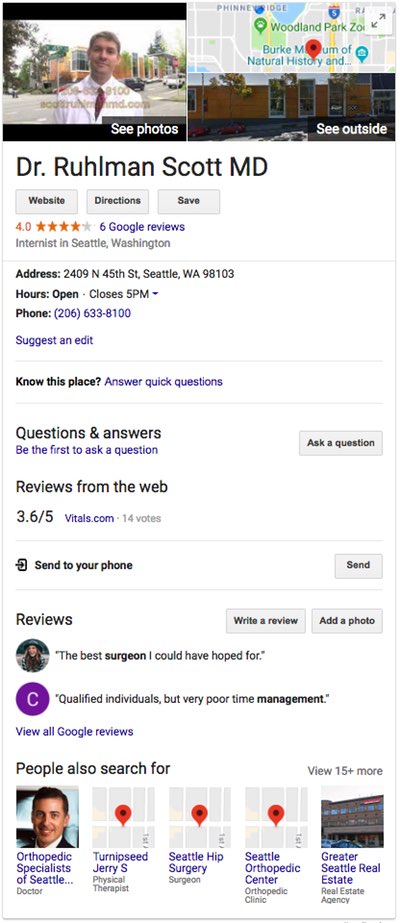
The seek for a second advice, Stacey Donion, MD, offers a really completely different expertise. Just like the Metropolis of Boston website above, Dr. Donion’s profile on the Kaiser Permanente web site is completely intelligible to a sighted human reader. However as a result of its markup is fully presentational, its content material is nearly invisible to software program brokers.
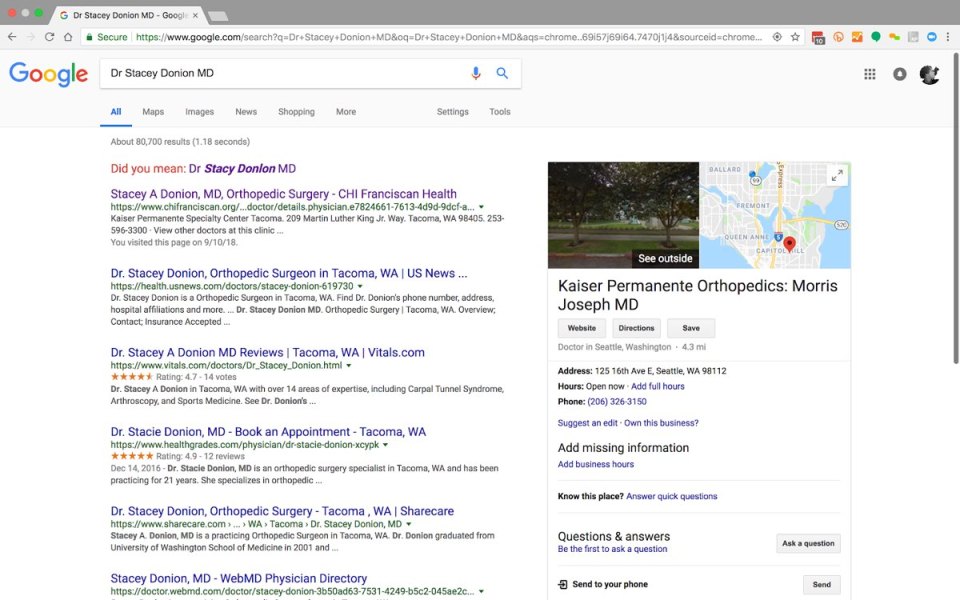
On this instance, we are able to see that Google is ready to discover loads of hyperlinks to Dr. Donion in its normal index outcomes, nevertheless it isn’t capable of “perceive” the details about these sources properly sufficient to current an aggregated end result. On this case, the Information Graph is aware of Dr. Donion is a Kaiser Permanente doctor, nevertheless it pulls within the improper location and the improper doctor’s identify in its try and construct a Information Graph show.
You’ll additionally discover that whereas Dr. Stacey Donion is an actual match in all the listed search outcomes—that are quite a few sufficient to fill the primary outcomes web page—we’re proven a “did you imply” hyperlink for a distinct physician. Stacy Donlon, MD, is a neurologist who practices at MultiCare Neuroscience Middle, which isn’t affiliated with Kaiser Permanente. Multicare does, nonetheless, present semantic and linked data-rich profiles for his or her physicians.
Voice queries and content material inference#section5
The growing prevalence of voice as a mode of entry to data makes offering structured, machine-intelligible content material all of the extra necessary. Voice and sensible software program brokers are usually not simply releasing customers from their keyboards, they’re altering person conduct. In accordance with LSA Insider, there are a number of necessary variations between voice queries and typed queries. Voice queries are usually:
- longer;
- extra prone to ask who, what, and the place;
- extra conversational;
- and extra particular.
In an effort to tailor outcomes to those extra particularly formulated queries, software program brokers have begun inferring intent after which utilizing the linked knowledge at their disposal to assemble a focused, concise response. If I ask Google Assistant what time Dr. Ruhlman’s workplace closes, as an illustration, it responds, “Dr. Ruhlman’s workplace closes at 5 p.m.,” and shows this end result:
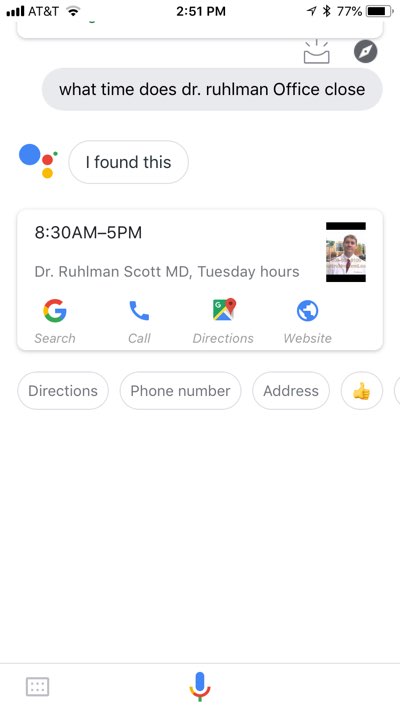
These outcomes are usually not solely aggregated from disparate sources, however are interpreted and remixed to offer a custom-made response to my particular query. Getting instructions, putting a cellphone name, and accessing Dr. Ruhlman’s profile web page on swedish.org are all on the ideas of my fingers.
After I ask Google Assistant what time Dr. Donion’s workplace closes, the end result just isn’t solely much less useful however truly factors me within the improper course. As a substitute of a focused number of targeted actions to comply with up on my question, I’m offered with the hours of operation and speak to data for MultiCare Neuroscience Middle.
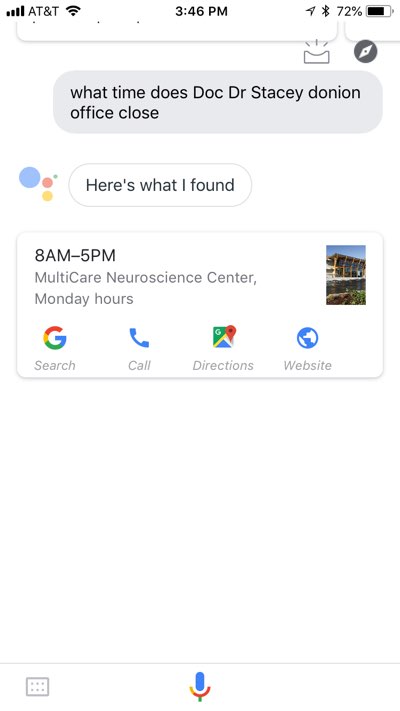
MultiCare Neuroscience Middle, you’ll recall, is the place Dr. Donlon—the neuroscientist Google thinks I could also be searching for, not the orthopedic surgeon I’m truly searching for—practices. Dr. Donlon’s profile web page, very similar to Dr. Ruhlman’s, is semantically structured and marked up with linked knowledge.
To be truthful, subsequent trials of this search did produce the generic (and partially incorrect) observe location for Dr. Donion (“Kaiser Permanente Orthopedics: Morris Joseph MD”). It’s attainable that by way of repeated publicity to the search time period “Dr. Stacey Donion,” Google Assistant fine-tuned the responses it supplied. The preliminary end result, nonetheless, means that sensible brokers could also be at the very least partially prone to the identical availability heuristic that impacts people, whereby the knowledge that’s best to recall usually appears essentially the most right.
There’s not sufficient proof on this small pattern to help a broad declare that algorithms have “cognitive” bias, however even once we permit for doubtlessly confounding variables, we are able to see the compounding issues we threat by ignoring structured content material. “Donlon,” for instance, might be a extra widespread identify than “Donion” and could also be simply mistyped on a QWERTY keyboard. Regardless, the Kaiser Permanente end result we’re given above for Dr. Donion is for the improper doctor. Moreover, within the Google Assistant voice search, the interplay format doesn’t confirm whether or not we meant Dr. Donlon; it simply offers us together with her facility’s contact data. In these circumstances, offering clear, machine-readable content material can solely work to our benefit.
The enterprise case for structured content material design#section6
In 2012, content material strategist Karen McGrane wrote that “you don’t get to resolve which platform or gadget your clients use to entry your content material: they do.”
This assertion was meant to assist designers, strategists, and companies put together for the approaching rise of cell. It continues to ring true for the period of linked knowledge. With the rising prevalence of sensible assistants and voice-based queries, a corporation’s web site is much less and fewer prone to be a possible customer’s first encounter with wealthy content material. In lots of circumstances—similar to discovering location data, hours, cellphone numbers, and scores—this pre-visit engagement could also be a person’s solely interplay with an data supply.
These sorts of fast interactions, nonetheless, are just one small piece of a a lot bigger subject: linked knowledge is more and more key to sustaining the integrity of content material on-line. The organizations I’ve used as examples, just like the hospitals, authorities businesses, and faculties I’ve consulted with for years, don’t measure the success of their communications efforts in web page views or advert clicks. Success for them means connecting sufferers, constituents, and neighborhood members with companies and correct details about the group, wherever that data could be discovered. This communication-based definition of success readily applies to nearly any kind of group working to additional its enterprise targets on the internet.
The mannequin of constructing pages after which anticipating customers to find and parse these pages to reply questions, although time-tested within the pre-voice period, is rapidly changing into inadequate for efficient communication. It precludes organizations from taking part in emergent patterns of data looking for and discovery. And—as we noticed within the case of trying to find details about physicians—it could lead software program brokers to make inferences based mostly on inadequate or faulty data, doubtlessly routing clients to opponents who talk extra successfully.
By speaking clearly in a digital context that now contains aggregation and inference, organizations are extra successfully capable of converse to their customers the place customers truly are, be it on a web site, a search engine outcomes web page, or a voice-controlled digital assistant. They’re additionally capable of keep larger management over the accuracy of their messages by guaranteeing that the proper content material may be discovered and communicated throughout contexts.
Getting began: who and the way#section7
Design practices that construct bridges between person wants and know-how necessities to fulfill enterprise targets are essential to creating this imaginative and prescient a actuality. Data architects, content material strategists, builders, and expertise designers all have a job to play in designing and delivering efficient structured content material options.
Practitioners from throughout the design neighborhood have shared a wealth of sources lately on creating content material programs that work for people and algorithms alike. To be taught extra about implementing a structured content material strategy to your group, these books and articles are an ideal place to begin: