Throughout my second lecture to an XML class at a neighborhood
group faculty, I defined how XML allows you to outline your individual markup language with customized tags and attributes. I had completed defining a easy markup language to be used
with a listing of newbie sports activities golf equipment, and had displayed a pattern doc
written with that markup. At that time, one pupil requested:
Article Continues Beneath
“Isn’t it inefficient to should kind all these tags for
each membership? What good is that this? It seems to be good, however what can I
do with this doc? How can I put this in an internet web page or use it with
different packages? Wouldn’t or not it’s simpler to only use HTML or a
database/phrase processor/fill-in-the-blank?”
The explanation that we use XML as an alternative of a particular utility is that
XML is not only a fairly face, dwelling in isolation from the remainder
of the computing world. XML is greater than a rulebook for producing
customized markup languages. It’s a part of a household of applied sciences, which,
working collectively, make your XML-based paperwork very helpful certainly. To
reveal what I imply, I made a decision to create a brand new XML-based markup
language from scratch, and present what you are able to do with a doc written
in that language, utilizing off-the-shelf instruments.
Making a New Markup Language#section2
The language that I created shops the dietary
info that you just discover on meals labels in the US. The
doc begins with a <vitamin> tag, adopted by
a <daily-values> ingredient that offers the utmost
quantities of fats, sodium, and so forth. for a 2000-calorie-a-day weight loss program, and the
items during which the quantity is measured.
The day by day values are adopted by a collection of<meals> components, every of which supplies info
a couple of particular meals and its dietary classes. As a result of the<daily-values> ingredient has already outlined the items
during which every class is measured, we don’t have to repeat them
for each meals; we simply enter the numbers for that individual
meals’s complete fats, sodium, and so forth. After the final meals, we shut the
doc with a closing </vitamin> tag.
<vitamin><!-- Set up the day by day values -->
<daily-values>
<total-fat items="g"> 65 </total-fat>
<saturated-fat items="g"> 20 </saturated-fat>
<ldl cholesterol items="mg"> 300 </ldl cholesterol>
<sodium items="mg"> 2400 </sodium>
<carb items="g"> 300 </carb>
<fiber items="g"> 25 </fiber>
<protein items="g"> 50 </protein>
</daily-values><p><!-- Now record the person meals --></p><meals>
<identify>Avocado Dip</identify>
<mfr>Sunnydale</mfr><serving items="g"> 29 </serving>
<energy complete="110" fats="100"/><total-fat> 11 </total-fat>
<saturated-fat> 3 </saturated-fat>
<ldl cholesterol> 5 </ldl cholesterol>
<sodium> 210 </sodium>
<carb> 2 </carb>
<fiber> 0 </fiber>
<protein> 1 </protein><nutritional vitamins>
<p> <a> 0 </a><br />
</p><c> 0 </c>
</nutritional vitamins><minerals>
<p> </p><ca> 0 </ca>
<p> </p><fe> 0 </fe>
</minerals>
</meals><p><!-- and so forth. --></p>
</vitamin>You may even see the complete doc
that’s used for the examples on this article. All of the numbers
are actual; solely the producers’ names have been modified
to guard the harmless and keep away from lawsuits.
A fast notice: nutritional vitamins and minerals are measured in percentages, not
grams or milligrams. That’s why we don’t want to ascertain
any items or maximums for them within the <daily-values>
ingredient.
I entered the information by hand utilizing the nedit program on
Linux. I might have used any editor that lets me save recordsdata
as plain ASCII textual content; notepad on Home windows or vi on Linux would have completed
equally effectively. To make knowledge entry simpler, I created an empty
“template” for a meals, which you see on the backside of the
file. I copied and pasted it for every new meals, in order that I didn’t
should kind the tags again and again.
What have we purchased by creating this XML file in a textual content
editor reasonably than creating an HTML doc or a spreadsheet or knowledge
base? First, the information is structured; it’s not only a mass of
numbers in an HTML desk or a textual content file of tab–separated values.
Due to the customized tags, it’s one thing that people can learn
and perceive. It’s additionally open; we don’t want some
costly, proprietary software program to extract the data from a
binary file. So, as a transport medium, XML already serves us
properly.
Validating the Doc#section4
Even in the event you’re the one one who ever enters
knowledge into the doc, you’d like to have the ability to test that you just
haven’t ignored any info or added additional tags.
Moreover, you’d prefer to make certain that your percentages are all
between 0 and 100.
This turns into much more necessary if many individuals enter knowledge. Even when
you give other people directions on the correct format, they might ignore
it or make errors. In brief, you wish to have the pc assist
you identify that the information in your paperwork is legitimate.
You do that by making a machine-readable grammar which
specifies which tags and attributes are legitimate, and in what
combos, and what values your tags and attributes could comprise.
You then hand your doc and the grammar to a program referred to as a
validator, and it checks that the doc matches your
specs.
One machine-readable type of specifying such a grammar is a notation
referred to as Chill out NG. Chill out NG is, itself, an XML-based markup
language. Its function is to specify what’s legitimate in different
markup languages. This isn’t as loopy or not possible because it
sounds. In any case, books that inform you how one can use English grammar
appropriately are additionally written in English.
For instance, one of many specs of our dietary markup
language is that the <energy> ingredient is an empty
ingredient, and it has two attributes, the complete attribute
and the fats attribute. These should each have decimal
numbers in them. We are saying this in Chill out NG as follows:
<ingredient identify="energy">
<empty/>
<attribute identify="complete"><knowledge kind="decimal"/>
</attribute>
<attribute identify="fats"><knowledge kind="decimal"/>
</attribute>
</ingredient>Once we move vitamin paperwork via the validator with this
doc, the validator will inform us that the primary tag under
is right, however the second isn’t.
<energy complete="100" fats="10"/>
<energy complete="217" fats="do not ask!"/>You may even see the complete grammar
specification for the vitamin markup right here. Chances are you’ll
additionally discover
out extra about Chill out NG. By the way in which,
Chill out NG is just not the one recreation on the town if you wish to specify
grammar. Chances are you’ll use one thing referred to as a DTD (Doc
Sort Definition), which isn’t as highly effective
as Chill out NG; or you might use XML Schema, which is
about as highly effective as Chill out NG, however way more complicated to be taught.
In case you are feeling adventurous, you might need to strive these
recordsdata your self. You have to some XML instruments as a way to
do that. Right here is how one can arrange the instruments
for Home windows, and right here’s the setup for Linux.
To validate a file, go to the command immediate in case you are utilizing
Home windows, or go to a console window and get a shell immediate in the event you
are utilizing Linux. Then use the batch/shell file described
within the setup directions to invoke
the Multi-Schema Validator:
msvalidate vitamin.rng vitamin.xml
Though we are able to enter readable knowledge and test to see if it’s
OK, we nonetheless can’t do something with it. If we show it
in a browser, we simply see the textual content all squeezed collectively. That’s
as a result of the browser doesn’t know how one can show a<meals> or <nutritional vitamins> tag.
In case you are utilizing the very newest browsers, you may
connect a stylesheet to the XML file. Now we have completed that in
this instance by placing this line on the prime of filevitamin.xml
<?xml model="1.0"?>
<?xml-stylesheet kind="textual content/css"
href="https://alistapart.com/article/usingxml/vitamin.css"?>
<vitamin></vitamin>The model sheet that we write for file vitamin.css
seems to be very very similar to the model sheets that you just use along with your HTML
recordsdata. The distinction is that we assign kinds to our new vitamin
tags, to not the usual HTML tags. For instance, to say {that a}
meals’s producer ought to seem in 16 level italic kind with out
beginning a brand new line, you’ll write:
mfr {
show: inline;
font-size: 16pt;
font-style: italic;
}After you have created
the complete stylesheet in the identical
listing because the XML file, you may open the XML file in a
fashionable browser corresponding to Mozilla, and it’ll show the data.
Transformation—A Higher Manner#section8
The issues with the stylesheet are that:
- It solely works with the very newest browsers that deal with
Cascading Type Sheets Degree 2. - It will probably’t extract all the data (for instance, the items
don’t present up within the output doc as a result of they’re
“hidden” within the attribute values. - It will probably’t calculate percentages.
Moreover, the markup we’ve invented right here is data-oriented;
it’s designed to explain knowledge to be saved or to be transmitted to
different packages. In these paperwork, the order of components and the sort
of knowledge in every ingredient is pretty inflexible. Stylesheets work higher with
narrative-oriented markup paperwork. These are paperwork which are
typically meant for human studying, and are extra “free-form”
than data-oriented paperwork. Examples of narrative-oriented markup are
XHTML, DocBook (a markup for writing books and articles), and NewsML
(for writing information studies).
So as to get round these issues, we are able to use XSLT,
Extensible Stylesheet Language Transformations, to transform the
vitamin file into different types. XSLT is, once more, one other XML-based
markup language. Its function is to explain how one can take enter from one
XML file (the “supply doc”) and output it to a outcome
doc. XSLT has the flexibleness to extract knowledge from attributes as
effectively as ingredient content material, and it could do calculation and sorting upon the
knowledge within the supply doc.
This energy makes XSLT a key know-how within the XML household of
applied sciences. For an excellent introduction, learn
Norman Walsh’s wonderful presentation on the topic or
this
hands-on tutorial.
Transformation to HTML#section9
The primary
XSLT file, which you may even see right here, converts the vitamin doc
into a really plain HTML file appropriate for show on any browser on a
desktop or PDA. To do the transformation, you’d kind this
command:
remodel vitamin.xml nutrition_plain.xslt nutrition_plain.html
The results of the transformation is an HTML file named nutrition_plain.html,
which you will open in any browser you want. Even this easy
transformation has completed two issues that we couldn’t do with CSS:
it makes use of the data in attributes to show the items for every
dietary class, and it calculates percentages of the day by day
values.
OK, so possibly you need one thing a bit fancier. Right here’s a extra complicated
transformation which kinds the information by the ratio of fats energy to
complete energy per serving; kind of a “healthiness
index.”
When you have saved the XSLT in a file referred to asnutrition_fancy.xslt you may kind this command:
remodel vitamin.xml
nutrition_fancy.xslt nutrition_fancy.htmlThat produces a file named
nutrition_fancy.html,
which seems to be remarkably completely different from the plain model. It makes use of
Cascading Type Sheets to provide the little bar graphs; you’ll
want a contemporary browser like Web Explorer 5+ or Mozilla/Netscape 6
to see the impact. Discover that XSLT allows you to decide and select the information
you need to show; the details about carbohydrates, fiber,
nutritional vitamins, and minerals are omitted within the fancy model. (They
might, after all, be added by altering the XSLT file.)
Now we have used XSLT to take the supply XML file and remodel
it to 2 completely different HTML recordsdata; a plain model that’s appropriate for
show on outdated browsers and PDAs, and a fancier model that’s
appropriate to be used with desktop computer systems and fashionable browsers.
Non-HTML Transformation#section11
However wait, possibly you don’t need HTML;
there’s extra than simply browsers on the earth, you realize. You may
need to take the information and convert it to a textual content file of tab–separated
values for import right into a spreadsheet or database program.
Here’s a
transformation file that does this, utilizing this command:
remodel vitamin.xml nutrition_csv.xslt vitamin.csv
And right here’s the ensuing textual content
file.
Let’s say you need to create a PDF file out of your
XML. That’s potential through the use of a metamorphosis to vary the XML to
one other markup language: XSL-FO (Extensible Stylesheet
Language – Formatting Objects). It is a web page format language. A instrument
referred to as FOP (Formatting Objects to PDF) takes that markup and
creates PDF recordsdata for you.
Here’s a transformation file which
takes the vitamin knowledge and converts it to formatting objects. If
you reserve it in nutrition_fo.xslt, you should use FOP to do
the conversion to PDF:
fop -xml vitamin.xml -xsl nutrition_fo.xslt -pdf vitamin.pdf
The result’s a PDF file; it
produces pages which are roughly 8 centimeters huge and 9
centimeters excessive, which inserts comfortably right into a shirt pocket.
Lastly, you might want to create an interactive, graphic
model of the information. One other XML-based markup,
SVG—Scalable Vector Graphics— provides you this
functionality. SVG has components like the next, which draw a black
diagonal line and a yellow circle with a inexperienced define:
<line x1="0" y1="0" x2="50" y2="50" />
<circle cx="100" cy="100" r="30" />Through the use of a metamorphosis file that
produces SVG, we are able to assemble a graphic that exhibits a bar graph for
the meals whose identify you click on. Right here’s what you kind:
remodel vitamin.xml nutrition_svg.xslt vitamin.svg
Chances are you’ll show the outcome with the SVG browser that’s a part of the
Batik toolkit. When you have put in Batik as per the directions
given for Linux or for Home windows, you kindbatik�nutrition.svg. I’ve not examined the file with
the most recent model of the Adobe SVG
Viewer, but it surely ought to work properly. Here’s a screenshot;
click on it to see it full dimension.
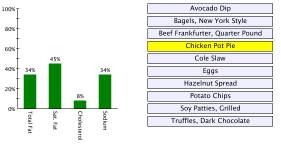
Different Methods to Use the XML Instruments#section14
On this article, we’ve used the Multi-Schema
Validator, Xalan Transformer, FOP converter, and Batik viewer from the
command immediate. That’s the quickest and best technique to get issues
working so that you could have an expertise of what XML can do.
The batch or shell file strategy would work in a manufacturing
atmosphere the place you generate an entire web site’s price of HTML
recordsdata from a number of XML recordsdata at common time intervals. You simply
arrange a batch job to run at scheduled occasions (a cron job
in Unix phrases) to generate the recordsdata you want.
What if that you must generate HTML pages or PDF recordsdata dynamically
in response to consumer requests? Clearly, you don’t need the overhead
of beginning a Java course of each time a request is available in, and a
static batch file actually gained’t do the trick. Each the
Multi-Schema Validator and Xalan have an API (Software Program
Interface) and might thus change into a part of a Java servlet operating on
your server and dealing with dynamic consumer requests. As soon as a servlet is
loaded, it stays in reminiscence, so there isn’t any additional overhead for
subsequent makes use of of a metamorphosis.
In case you are eager about operating servlets, one possibility is to make use of the
Jakarta Tomcat servlet container. It will probably run as a stand-alone server for testing or as a
module for both Apache or Microsoft IIS.
There are two points to timing: how lengthy it takes to
write the grammars and transformations, and how briskly they run.
Designing the markup
language took me about 25 minutes, and getting into the information took me
one other 25 minutes, a few of it operating out to the kitchen to seize objects
from the shelf or fridge. Writing and testing the Chill out NG
grammar required half-hour.
The Cascading Type Sheet for displaying the XML instantly in Mozilla
took all of quarter-hour to put in writing. The “plain HTML”
transformation took about 50 minutes, together with time for trying up
some XSLT constructs and doing a little experimentation. The
“fancy” transformation took 45 minutes. I wanted 20 minutes
to determine how one can do the bar graphs with stylesheets within the first
place, and I used one other 5 minutes for minor aesthetic changes.
The file for conversion to tab–separated values was a fifteen-minute
job.
The transformation for PDF took an hour. The primary time via, I
designed it for paper the scale of a compact disc insert. I believed
higher of it, and determined to cut back it to shirt-pocket dimension. That took
one other 30 to 45 minutes of tweaking and getting the font sizes simply
the way in which I needed them. I additionally needed to make some modifications to keep away from utilizing
elements of XSL Formatting Objects that FOP doesn’t implement but.
Lastly, the SVG transformation took an hour and a half to put in writing.
About half that point was experimenting to get every part positioned
properly and making the ECMA Script interplay work correctly.
You don’t should be an professional at Chill out NG, XSLT, XSL
Formatting Objects, or SVG to do that. I don’t use any of those
techonlogies every day. I simply know sufficient about every of them
to get issues to work. On this case, my philosophy was “the primary
means you consider that works is the suitable means.” That’s the reason XSLT
specialists will probably be shocked once they see an inefficient assemble like
this within the plain HTML remodel file.
choose="/vitamin/daily-values/*[name(.)=name($node)]/@items"This isn’t to say that there isn’t any studying concerned right here; you’ll
have to spend a while on that. You don’t have to spend a
lifetime on it, although. It’s undoubtedly potential to be taught sufficient about
these applied sciences to place them to efficient use in a short while.
I examined all of those recordsdata on a 400MHz AMD Ok-6 with
128Mb of reminiscence operating SuSE Linux
7.2. For the transformations, I modified the SimpleTransform.java
pattern program that comes with Xalan. This program data the entire
time to generate the output and the time concerned in transformation
after the XSLT file has been parsed. In case you are operating transformations
on a server, you may cache the parsed XSLT file, so the overhead for
parsing happens solely as soon as.
| Transformation | Time in seconds | |
|---|---|---|
| Complete | Remodel | |
| Plain HTML | 3.691 | 1.018 |
| Fancy HTML | 4.057 | 1.409 |
| Tab–separated Values | 3.057 | 0.548 |
| SVG | 3.386 | 0.689 |
I measured the time for the PDF transformation with the
Linux time command. Producing the file took
15.115 seconds actual time, with 10.920 seconds of consumer CPU time.
In fact, these should not the one instruments out there. There are different
XSLT processors and different packages for changing XSL Formatting
Objects to PDF. I selected MSV, Xalan, Fop, and Batik as a result of they’re
free, simple to make use of, and I used to be already conversant in them.
-
Utilizing XML-based markup provides your doc construction,
and makes it readable and open. -
XML is a part of a household of applied sciences.
-
You should utilize grammar markup languages like Chill out NG
or XML Schema to validate
your paperwork. -
You should utilize XSLT transformations to repurpose a doc.
A single doc can function the supply for XHTML, plain textual content,
PDF, or different XML markup languages like SVG. -
Packages which do validation and transformation are freely
out there and simple to make use of.
These capabilities exist proper now, and they’re simple to be taught and
make the most of. That’s the reason XML is sweet, and why persons are so enthusiastic about
it as soon as they begin to use it.
Chances are you’ll obtain the
XML recordsdata and the ensuing HTML, textual content, and PDF recordsdata.