
In our earlier section, “Server to Shopper,” we noticed how a URL is requested from a server and discovered all concerning the many situations and caches that assist optimize supply of the related useful resource. As soon as the browser engine lastly will get the useful resource, it wants to start out turning it right into a rendered net web page. On this section, we focus totally on HTML assets, and the way the tags of HTML are remodeled into the constructing blocks for what is going to finally be offered on display screen.
Article Continues Beneath
To make use of a development metaphor, we’ve drafted the blueprints, acquired all of the permits, and picked up all of the uncooked supplies on the development website; it’s time to start out constructing!
As soon as content material will get from the server to the consumer by the networking system, its first cease is the HTML parser, which consists of some methods working collectively: encoding, pre-parsing, tokenization, and tree development. The parser is the a part of the development challenge metaphor the place we stroll by all of the uncooked supplies: unpacking containers; unbinding pallets, pipes, wiring, and many others.; and pouring the inspiration earlier than handing off every little thing to the consultants engaged on the framing, plumbing, electrical, and many others.
The payload of an HTTP response physique could be something from HTML textual content to picture knowledge. The primary job of the parser is to determine interpret the bits simply obtained from the server. Assuming we’re processing an HTML doc, the decoder should determine how the textual content doc was translated into bits as a way to reverse the method.
| Characters | D | O | M |
|---|---|---|---|
| ASCII Values | 68 | 79 | 77 |
| Binary Values | 01000100 | 01001111 | 01001101 |
| Bits | 8 | 8 | 8 |
(Do not forget that in the end even textual content should be translated to binary within the pc. Encoding—on this case ASCII encoding—defines {that a} binary worth similar to “01000100” means the letter “D,” as proven within the determine above.) Many attainable encodings exist for textual content—it’s the browser’s job to determine correctly decode the textual content. The server ought to present hints by way of Content material-Kind headers, and the main bits themselves could be analyzed (for a byte order mark, or BOM). If the encoding nonetheless can’t be decided, the browser can apply its finest guess primarily based on heuristics. Typically the one definitive reply comes from the (encoded) content material itself within the type of a <meta> html tag. Worst case state of affairs, the browser makes an informed guess after which later finds a contradicting <meta> tag after parsing has began in earnest. In these uncommon instances, the parser should restart, throwing away the beforehand decoded content material. Browsers generally must take care of previous net content material (utilizing legacy encodings), and numerous these methods are in place to assist that.
When saving your HTML paperwork for the online as we speak, the selection is obvious: use UTF-8 encoding. Why? It properly helps the total Unicode vary of characters, has good compatibility with ASCII for single-byte characters frequent to languages like CSS, HTML, and JavaScript, and is more likely to be the browser’s fallback default. You’ll be able to inform when encoding goes mistaken, as a result of textual content gained’t render correctly (you’ll are inclined to get rubbish characters or containers the place legible textual content is often seen).
Pre-parsing/scanning#section4
As soon as the encoding is understood, the parser begins an preliminary pre-parsing step to scan the content material with the aim of minimizing round-trip latency for extra assets. The pre-parser just isn’t a full parser; for instance, it doesn’t perceive nesting ranges or mum or dad/baby relationships in HTML. Nevertheless, the pre-parser does acknowledge particular HTML tag names and attributes, in addition to URLs. For instance, if in case you have an <img src="https://someplace.instance.com/photographs/canine.png" alt=""> someplace in your HTML content material, the pre-parser will discover the src attribute, and queue a useful resource request for the canine image by way of the networking system. The canine picture is requested as rapidly as attainable, minimizing the time you should watch for it to reach from the community. The pre-parser may discover sure express requests within the HTML similar to preload and prefetch directives, and queue these up for processing as properly.
Tokenization#section5
Tokenization is the primary half of parsing HTML. It entails turning the markup into particular person tokens similar to “start tag,” “finish tag,” “textual content run,” “remark,” and so forth, that are fed into the subsequent state of the parser. The tokenizer is a state machine that transitions between the totally different states of the HTML language, similar to “in tag open state” (<|video controls>), “in attribute title state” (<video con|trols>), and “after attribute title state” (<video controls|>), doing so iteratively as every character within the HTML markup textual content doc is learn.
(In every of these instance tags, the vertical pipe illustrates the tokenizer’s place.)
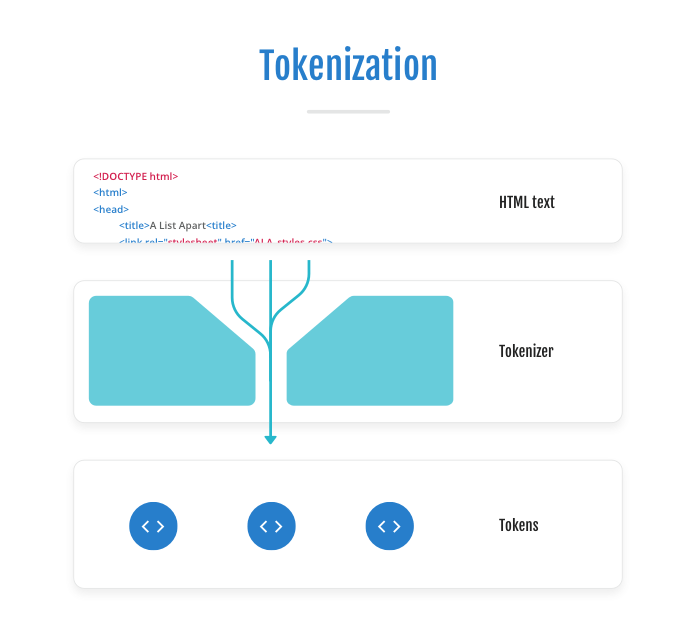
The HTML spec (see “12.2.5 Tokenization”) at present defines eighty separate states for the tokenizer. The tokenizer and parser are very adaptable: each can deal with and convert any textual content content material into an HTML doc—even when code within the textual content just isn’t legitimate HTML. Resiliency like this is among the options that has made the online so approachable by builders of all ability ranges. Nevertheless, the downside of the tokenizer and parser’s resilience is that you could be not at all times get the outcomes you count on, which may result in some delicate programming bugs. (Checking your code within the HTML validator may also help you keep away from bugs like this.)
For individuals who desire a extra black-and-white strategy to markup language correctness, browsers have an alternate parsing mechanism inbuilt that treats any failure as a catastrophic failure (that means any failure will trigger the content material to not render). This parsing mode makes use of the principles of XML to course of HTML, and could be enabled by sending the doc to the browser with the “utility/xhtml+xml” MIME sort (or any XML-based MIME sort that makes use of components within the HTML namespace).
Browsers might mix the pre-parser and tokenization steps collectively as an optimization.
Parsing/tree development#section6
The browser wants an inside (in-memory) illustration of an online web page, and, within the DOM commonplace, net requirements outline precisely what form that illustration ought to be. The parser’s duty is to take the tokens created by the tokenizer within the earlier step, and create and insert the objects into the Doc Object Mannequin (DOM) within the acceptable method (particularly utilizing the twenty-three separate states of its state machine; see “12.2.6.4 The foundations for parsing tokens in HTML content material”). The DOM is organized right into a tree knowledge construction, so this course of is typically known as tree development. (As an apart, Web Explorer didn’t use a tree construction for a lot of its historical past.)
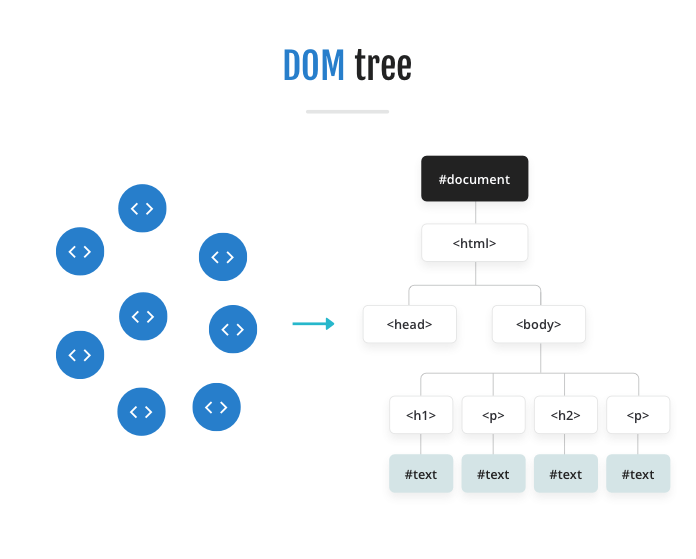
HTML parsing is difficult by the number of error-handling instances that be sure that legacy HTML content material on the internet continues to have appropriate construction in as we speak’s fashionable browsers. For instance, many HTML tags have implied finish tags, that means that if you happen to don’t present them, the browser auto-closes the matching tag for you. Take into account, for example, this HTML:
<p>sincerely<p>The authors</p>The parser has a rule that can create an implied finish tag for the paragraph, like so:
<p>sincerely</p><p>The authors</p>This ensures the 2 paragraph objects within the ensuing tree are siblings, versus one paragraph object by ignoring the second open tag. HTML tables are maybe essentially the most difficult the place the parser’s guidelines try to make sure that tables have the right construction.
Regardless of all of the difficult parsing guidelines, as soon as the DOM tree is created, all the parsing guidelines that attempt to create a “appropriate” HTML construction are not enforced. Utilizing JavaScript, an online web page can rearrange the DOM tree in nearly any method it likes, even when it doesn’t make sense! (For instance, including a desk cell because the baby of a <video> tag). The rendering system turns into liable for determining take care of any bizarre inconsistencies like that.
One other complicating think about HTML parsing is that JavaScript can add extra content material to be parsed whereas the parser is in the course of doing its job. <script> tags include textual content that the parser should gather after which ship to a scripting engine for analysis. Whereas the script engine parses and evaluates the script textual content, the parser waits. If the script analysis consists of invoking the doc.write API, a second occasion of the HTML parser should begin operating (reentrantly). To rapidly revisit our development metaphor, <script> and doc.write require stopping all in-progress work to return to the shop to get some further supplies that we hadn’t realized we would have liked. Whereas we’re away on the retailer, all progress on the development is stalled.
All of those problems make writing a compliant HTML parser a non-trivial endeavor.
When the parser finishes, it broadcasts its completion by way of an occasion referred to as DOMContentLoaded. Occasions are the printed system constructed into the browser that JavaScript can hear and reply to. In our development metaphor, occasions are the reviews that varied staff carry to the foreman after they encounter an issue or end a process. Like DOMContentLoaded, there are a number of occasions that sign vital state modifications within the net web page similar to load (that means parsing is finished, and all of the assets requested by the parser, like photographs, CSS, video, and many others., have been downloaded) and unload (that means the online web page is about to be closed). Many occasions are particular to person enter, such because the person touching the display screen (pointerdown, pointerup, and others), utilizing a mouse (mouseover, mousemove, and others), or typing on the keyboard (keydown, keyup, and keypress).
The browser creates an occasion object within the DOM, packs it stuffed with helpful state data (similar to the situation of the contact on the display screen, the important thing on the keyboard that was pressed, and so forth), and “fires” that occasion. Any JavaScript code that occurs to be listening for that occasion is then run and supplied with the occasion object.
The tree construction of the DOM makes it handy to “filter” how steadily code responds to an occasion by permitting occasions to be listened for at any degree within the tree (i.e.., on the root of the tree, within the leaves of the tree, or wherever in between). The browser first determines the place to fireplace the occasion within the tree (that means which DOM object, similar to a selected <enter> management), after which calculates a route for the occasion ranging from the basis of the tree, then down every department till it reaches the goal (the <enter> for instance), after which again alongside the identical path to the basis. Every object alongside the route then has its occasion listeners triggered, in order that listeners on the root of the tree will “see” extra occasions than particular listeners on the leaves of the tree.
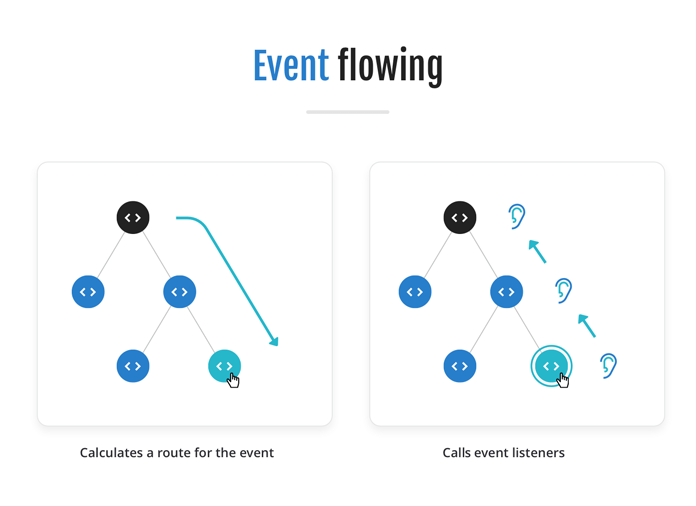
Some occasions can be canceled, which offers, for instance, the flexibility to cease a type submission if the shape isn’t crammed out correctly. (A submit occasion is fired from a <type> ingredient, and a JavaScript listener can verify the shape and optionally cancel the occasion if fields are empty or invalid.)
The HTML language offers a wealthy characteristic set that extends far past the markup that the parser processes. The parser builds the construction of which components include different components and what state these components have initially (their attributes). The mix of the construction and state is sufficient to present each a primary rendering and a few interactivity (similar to by built-in controls like <textarea>, <video>, <button>, and many others.). However with out the addition of CSS and JavaScript, the online could be very boring (and static). The DOM offers a further layer of performance each to the weather of HTML and to different objects that aren’t associated to HTML in any respect.
Within the development metaphor, the parser has assembled the ultimate constructing—all of the partitions, doorways, flooring, and ceilings are put in, and the plumbing, electrical, fuel, and such, are prepared. You’ll be able to open the doorways and home windows, and switch the lights on and off, however the construction is in any other case fairly plain. CSS offers the inside particulars—coloration on the partitions and baseboards, for instance. (We’ll get to CSS within the subsequent installment.) JavaScript allows entry to the DOM—all of the furnishings and home equipment inside, in addition to the providers exterior the constructing, such because the mailbox, storage shed and instruments, photo voltaic panels, water properly, and many others. We describe the “furnishings” and out of doors “providers” subsequent.
Factor interfaces#section9
Because the parser is developing objects to place into the tree, it appears up the ingredient’s title (and namespace) and finds an identical HTML interface to wrap across the object.
Interfaces add options to primary HTML components which can be particular to their form or sort of ingredient. Some generic options embody:
- entry to HTML collections representing all or a subset of the ingredient’s kids;
- the flexibility to look the ingredient’s attributes, kids, and mum or dad components;
- and importantly, methods to create new components (with out utilizing the parser), and connect them to (or detach them from) the tree.
For particular components like <desk>, the interface accommodates further table-specific options for finding all of the rows, columns, and cells inside the desk, in addition to shortcuts for eradicating and including rows and cells from and to the desk. Likewise, <canvas> interfaces have options for drawing strains, shapes, textual content, and pictures. JavaScript is required to make use of these APIs—they aren’t obtainable utilizing HTML markup alone.
Any DOM modifications made to the tree by way of the APIs described above (such because the hierarchical place of a component within the tree, the ingredient’s state by toggling an attribute title or worth, or any of the API actions from a component’s interface) after parsing ends will set off a chain-reaction of browser methods whose job is to research the change and replace what you see on the display screen as quickly as attainable. The tree maintains many optimizations for making these repeated updates quick and environment friendly, similar to:
- representing frequent ingredient names and attributes by way of a quantity (utilizing hash tables for quick identification);
- assortment caches that keep in mind a component’s frequently-visited kids (for quick child-element iteration);
- and sub-tree change-tracking to reduce what components of the entire tree get “soiled” (and can have to be re-validated).
Different APIs#section10
The HTML components and their interfaces within the DOM are the browser’s solely mechanism for displaying content material on the display screen. CSS can have an effect on format, however just for content material that exists in HTML components. Finally, if you wish to see content material on display screen, it should be executed by HTML interfaces which can be a part of the tree.” (For these questioning about Scalable Vector Graphics (SVG) and MathML languages—these components should even be added to the tree to be seen—I’ve skipped them for brevity.)
We discovered how the parser is a method of getting HTML from the server into the DOM tree, and the way ingredient interfaces within the DOM can be utilized so as to add, take away, and modify that tree after the actual fact. But, the browser’s programmable DOM is sort of huge and never scoped to only HTML ingredient interfaces.
The scope of the browser’s DOM is akin to the set of options that apps can use in any working system. Issues like (however not restricted to):
- entry to storage methods (databases, key/worth storage, community cache storage);
- gadgets (geolocation, proximity and orientation sensors of varied varieties, USB, MIDI, Bluetooth, Gamepads);
- the community (HTTP exchanges, bidirectional server sockets, real-time media streaming);
- graphics (2D and 3D graphics primitives, shaders, digital and augmented actuality);
- and multithreading (shared and devoted execution environments with wealthy message passing capabilities).
The capabilities uncovered by the DOM proceed to develop as new net requirements are developed and carried out by main browser engines. Most of those “further” APIs of the DOM are out of scope for this text, nevertheless.
Shifting on from markup#section11
On this section, you’ve discovered how parsing and tree development create the inspiration for the DOM: the stateful, in-memory illustration of the HTML tags obtained from the community.
With the DOM mannequin in place, providers such because the occasion mannequin and ingredient APIs allow net builders to alter the DOM construction at any time. Every change begins a sequence of “re-building” work of which updating the DOM is just step one.
Going again to the development analogy, the on-site uncooked supplies have been shaped into the structural framing of the constructing and constructed to the precise dimensions with inside plumbing, electrical, and different providers put in, however with no actual sense but of the constructing’s remaining look—its exterior and inside design.
Within the subsequent installment, we’ll cowl how the browser takes the DOM tree as enter to a format engine that comes with CSS and transforms the tree into one thing you may lastly see on the display screen.