
Most of us create identities throughout the online with out a lot acutely aware thought. We fill in profiles, add photographs, movies, opinions, and bookmarks. Though this data is commonly public, it’s fragmented into the silos of particular person web sites. Wouldn’t or not it’s a bit magical if, while you signed up for a brand new website, the location mentioned one thing like, “We discover you’ve a profile picture on Flickr and Twitter, would you want to make use of a type of or add a brand new one?” I constructed a JavaScript library that may show you how to just do that. Ident Engine discovers and retrieves distributed identities and user-generated content material that can assist you construct a bit magic into your consumer interfaces.
Article Continues Under
Attempt it out! Enter your profile URLs into the lifestream and mixed profile demos. Had been you shocked by the extent of element it came upon about you? Let me present you the way it works.
Our footprints throughout the online#section2
Social media websites encourage us to have extra open and clear conversations, and create alternatives for brand new folks to take part in our lives. We frequently see these distributed identities within the “elsewhere on the internet” design sample, by which folks listing their social media website profiles like this:
- Elsewhere on the internet:
- Locations yow will discover me:
Most of those identities are tied into social media websites the place we create content material. Most internet identities are distributed—constructed from a mesh of interlinked profiles, every of which comprises a wealth of data. These identities are our digital footprints throughout the online. APIs that use the semantic internet and open knowledge codecs are on the coronary heart of the structure that brings all our footprints collectively.
The semantic internet and open format knowledge#section3
The semantic internet makes an attempt to make data that’s presently solely intelligible to people machine readable. Microformats are the semantic internet know-how that presently exhibits essentially the most sensible promise. Microformats are small patterns of sophistication names and attributes you’ll be able to add to HTML to assist outline blocks of reusable semantic knowledge. There’s much more data on the internet formatted with microformats than most individuals understand: Yahoo’s SearchMonkey just lately discovered 1.35 billion profiles marked up with the microformat hCard. Many different microformats are used to mark up different kinds of user-generated content material, from prolonged opinions to tiny Twitter updates.
Past microformats, different open knowledge codecs such RDF, RSS, and ATOM comprise wealthy knowledge we will use.
Most of our internet footprints are encapsulated in open-standard knowledge codecs. To take advantage of the worth of those fragments, all we’d like is a machine-readable methodology to hyperlink the fragments to their frequent proprietor. This can be a job for XFN (XHTML Mates Community).
The facility of rel=“me” and Google’s Social Graph API#section4
XFN is a straightforward and highly effective microformat. We will use XFN to outline an interlinking set of internet pages that collectively, symbolize a person. To realize this, merely add the rel=“me” attribute to any hyperlink between two internet pages that symbolize the identical individual. For instance, I might use the markup beneath to outline a relationship between any web page on the internet that represented me and my Twitter profile:
rel="me" href="http://twitter.com/glennjones">Twitter
Simply over a 12 months in the past, Google launched the Social Graph API, which permits anybody to question these relationships. After you present a URL place to begin, it returns a map (social graph) of all of the associated pages (edges) linked by rel=“me” hyperlinks. Utilizing this API, you’ll be able to uncover the quite a few identities folks have throughout the online. Check out the id discovery demo. You’ll discover that outcomes range relying on what number of social media websites a person makes use of and the way properly these websites are interlinked. Typically, altering the start line returns completely different outcomes.
The 2 methods your identities are discovered#section5
There are two alternative ways to retrieve data from the Social Graph API utilizing its rel=“me” relationships. The best approach is otherme, which returns a listing of web sites based mostly on rel=“me”. Do this instance: http://socialgraph.apis.google.com/otherme?q=http://www.glennjones.web/&fairly=1
The second and extra low stage Social Graph API name, lookup means that you can management the inclusion of inward and outward linking. It additionally returns extra complicated hyperlink relationship views. The 2 major parameters of this name are edo (edges outward) and edi (edges inward).
Right here’s a take a look at the output of a lookup name for glennjones.web: http://socialgraph.apis.google.com/lookup?q=http://www.glennjones.web/&fme=1&edi=0&edo=1&fairly=1&jme=1
If we executed an API name towards the social graph within the diagram beneath to search out solely the outward relationships (i.e., edi=0&edo=1), it will return my weblog, my Final.fm profile, my Google profile, and my Flickr pages. Whereas if we executed an API name to search out each the outward and inward relationships (i.e., edi=0&edo=1), the Social Graph API would additionally discover my Brightkite web page.
Google’s testparse is a helpful debugging methodology that shows the connection hyperlinks Google finds in a given piece of HTML.
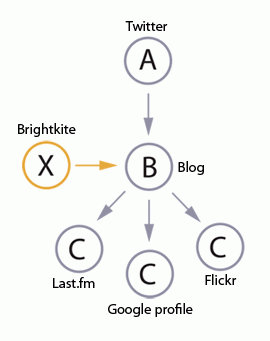
Fig. 1. Node linking diagram
Of the 2 strategies to question the social graph, the primary is to begin at level A (the primary URL) and observe all of the outward hyperlinks to different pages (edges) utilizing rel=“me”. Within the diagram, A hyperlinks to B after which B hyperlinks to all of the C pages. The hyperlinks from A to B to C are referred to as a series.
Solely search engines like google and yahoo, akin to Google, can use the second methodology, which is to seek for any inward rel=“me” hyperlinks from different webpages (edges). For instance, level X, (my Brightkite trương mục) has a rel=“me” hyperlink to my weblog, however there’s no strategy to discover level X following hyperlinks from level A. It’s essential to do a search of each web page to search out level X.
The otherme API name solely makes use of outward relationships. It returns dependable verified linkages, however typically, the outcomes are restricted.
Imposters and rogue relationships#section6
These strategies of extrapolating relationship knowledge are all the time all the time open to errors and potential abuse. When you use solely outward linking (i.e., the otherme API name), the outcomes are normally stable. It’s because the identical particular person ought to personal every of the pages within the chain, so the method is tough to hijack. Sadly, the otherme methodology doesn’t return as many outcomes as it will together with inward claims.
However you’ll be able to’t actually belief inward claims. Any imposter can embody a rel=“me” hyperlink on a web page to hijack another person’s social graph. Individuals can copy and paste HTML containing semantic markup into the incorrect context by mistake, creating rogue relationship hyperlinks. With some cautious post-processing, nevertheless, you should utilize inward-linking knowledge in case you’re keen to simply accept the odd error and rogue relationship in alternate for a fuller set of outcomes.
The choice to make use of inward claims needs to be based mostly on the kind of interface you might be constructing and your viewers’s expectations. If it’s essential play it protected, use solely the otherme methodology name. Over time, folks will create stronger linkages between their identities and utilizing inward claims will develop into pointless.
Past itemizing identities: social graph node mapping#section7
The Social Graph API returns interlinked web page URLs and can even present extra detailed data from some social media websites. Utilizing a method referred to as “social graph node mapping,” it finds helpful URLs associated to the identical particular person on a website. For sure accounts, it may additionally deliver again some small bits of information such because the consumer’s full title.
To extract this second tier of data, the API should create a canonical consumer trương mục referred to as SGN (Social Graph Normalized URL). For instance, utilizing an SGN, my trương mục on Flickr is expressed as: sgn://flickr.com/?ident=glennjonesnet. This area/username pairing can be utilized to search out different URLs (service endpoints). Utilizing the node mapping method, the outcomes for my trương mục on Flickr appear to be this:
"sgn://flickr.com/?ident=glennjonesnet": {
"attributes": {
"url": "http://www.flickr.com/photographs/glennjonesnet/",
"profile": "http://www.flickr.com/folks/glennjonesnet/",
"rss":http://api.flickr.com/companies/...",
"atom":"http://api.flickr.com/companies/...",
},Enhancing the invention course of#section8
To reinforce SGN, I added my very own customized knowledge to the API’s output. This enables me to explain many extra websites and repair endpoints, and—extra importantly—to programmatically retrieve content material from these websites.
| uri-template | http://www.flickr.com/folks/murtaugh/ |
| media-type | Html |
| schema | hCard |
| content-type | Profile |
Utilizing this knowledge, we will cross-reference the accounts the Social Graph API finds to determine particular knowledge we need to retrieve. With API endpoint discovery, we will goal particular content material varieties from throughout a person’s accounts. To reinforce the id knowledge we’ve thus far, we accumulate all of the obtainable profiles from throughout the online. Check out the profiles demo to be taught extra.
Though the hCard format is complete, it’s typically used to carry solely two items of data, akin to title and URL.
It is sensible to mixture our assortment of profiles right into a single, mixed profile. The aggregation guidelines Ident Engine makes use of favor completeness, and thus favor business-related knowledge sources over private knowledge sources. For instance, the handle is chosen by the variety of knowledge components it comprises. Some values akin to title, username, and URL are based mostly on essentially the most generally used worth throughout all of the profiles. Check out the mixed profile demo to be taught extra.
Mixing profile and social graph knowledge#section9
You should use the profiles to to assist lengthen your social graph. Profiles marked up in hCard can comprise a number of URLs. Most social media websites mark these URLs with rel=“me”, however some don’t. Typically you’ll be able to uncover new profiles by checking the URLs listed. Ident Engine additionally aggregates the information to search out the highest usernames and the first URL outlined throughout all of the profiles. This knowledge helps to resolve ambiguity points, akin to figuring out which hCard is the consultant hCard on any given web page.
Parsing profiles—you’ve acquired decisions#section10
There are a number of completely different microformat parsers you should utilize to parse hCard profiles. At the moment, Ident Engine makes use of two: Yahoo’s YQL and my very own .Internet parser, UfXtract. YQL parses microformats straight from Yahoo’s search index, and supplies a quick, dependable URL-based API. Its index doesn’t embody all of the pages on the internet, however while you want responsiveness and scalability, YQL is your best option. It could actually return XML or JSON. Right here’s an instance question utilizing YQL microformats:
choose * from microformats the place url="http://www.glennjones.web/about/"
http://question.yahooapis.com/v1/public/yql?q=choose * from microformats the place url=‘http:%2
F/www.glennjones.web/about/’&format=xml
The UfXtract parser is extra compliant to microformat specs and parses complicated microformat markup. Nonetheless, the UfXtract API is best suited to private hacks and initiatives than to large-scale business use. It can also return XML or JSON. Right here’s an instance UfXtract API name:
http://ufxtract.com/api/?url=http://www.glennjones.web/about/&format=hCard&output=xml
Different good parsers embody Optimus, hKit, and Swignition.
Retrieving user-generated content material#section11
Profiles should not the one sort of content material API endpoints can describe. We will additionally goal different open commonplace knowledge sources. In actual fact, it’s potential to construct a reasonably full lifestreaming software from these sources. Check out the lifestream demo to see this concept in motion.
The lifestream demo content material is parsed from RSS, Atom, or microformats. Though there are various server-side libraries for parsing RSS and Atom feeds when working client-side, the YQL API can efficiently parse most feeds and convert them right into a single XML or JSON format. Right here’s an instance YQL feed question:
(Line wraps marked » —Ed.)
choose * from feed
the place url="http://api.flickr.com/companies/feeds/ »
photos_public.gne?id=77314934@N00"http://question.yahooapis.com/v1/public/yql?q=choose * from feed the place url=‘http://api.flickr.com
/companies/feeds/photos_public.gne?id=77314934@N00’&format=xml
The API can return further details about embedded wealthy media sources, akin to photos or audio. You’ll be able to encapsulate all kinds of content material in feeds, so Ident Engine’s overlay knowledge has a “content-type” property for every API endpoint. This describes the content material as an occasion, exercise stream, standing, or video, and many others. With this data, you’ll be able to current content material in an affordable context.
Utilizing feeds doesn’t preclude utilizing microformats as a technique of accumulating content material. There are various circumstances by which microformats have benefits over feeds. For instance, I can use the hAtom microformat to extract Twitter statuses, however their equal RSS feeds should not publicly accessible.
http://ufxtract.com/api/?url=http://twitter.com/glennjones&format=hAtom&output=xml
It may be very disconcerting for customers to confront the information you’ve found utilizing these strategies. They could even be unaware that they’d shared the knowledge publicly. It’s necessary to coach internet customers about how they current themselves, and about which content material they select to make public.
Instruments such because the social graph API and knowledge codecs akin to microformats don’t degrade privateness—on the internet, there is no such thing as a actual privateness in obscurity—however as designers and builders, we have to discover higher methods to encourage customers to make knowledgeable selections about privateness. Most social media website approaches to privateness (and persona projection) are insufficient and unsophisticated in comparison with the methods by which we cope with privateness in the true world.
To create belief when designing interfaces that accumulate private profile knowledge, we have to be as clear as potential, and supply hyperlinks to the unique sources. If customers discover knowledge that’s incorrect or outdated, they need to have entry to a straightforward methodology of monitoring down that data to allow them to appropriate it.
Take into account your viewers #section13
The strategies we’ve examined work finest for sure audiences below particular circumstances—for instance, customers of web sites or purposes that present companies to different social media websites. In such instances, you’ll typically ask for trương mục particulars as a part of the primary interplay with new customers, and your viewers is by definition actively taking part in self publishing.
Use progressive enhancement#section14
Be sure you take into account progressive enhancement while you design interface performance round one of these data discovery. By no means rely fully on the information amount or high quality returned. As a substitute, design your discovery options to complement the principle activity stream. For instance, in case you design a sensible picture picker, present a file add as a place to begin, and supply enhanced discovery as an non-compulsory further.
All wrapped up for you: Ident Engine#section15
We’ve coated find out how to be a part of social graph and profile knowledge, however a couple of secondary issues stay. Moderately than going into larger element, I created a JavaScript library, and I invite the extra technically curious amongst you to drag it to items to learn how all of the cogs match collectively. For these much less technically curious amongst you, I hope it is going to be comparatively straightforward to make use of.
The library makes use of jQuery, so initiating a search is easy. First, it’s essential bind a operate to render your outcomes to the library. Within the code beneath I sure a name to the renderListing operate into any replace occasions fired by Ident Engine. The library will fireplace an replace each time it finds new knowledge in the course of the search course of.
jQuery(doc).prepared(operate () {
doc.bind('ident:replace', renderListing);
ident.useInwardEdges = true;
var url="http://twitter.com/glennjones
ident.search(url);
});
The render operate first clears any earlier content material. Then, it loops across the array of objects, on this case, to render any profile URLs discovered.
operate renderListing(e){
resetContent();
var ul = jQuery("
- ‘).appendTo(“˜outcomes’);
- ‘ + profileUrl + ‘
for (var x = 0; x < ident.indenties.size; x++) {
var profileUrl = ident.identities[x].profileUrl;
jQuery(‘
‘).appendTo(ul);
}
}
operate resetContent(){
jQuery('#outcomes').html('');
}
Parsing consumer content material with Ident Engine#section16
There are a number of methods to extract user-generated content material from the API endpoints Ident Engine discovers. The next two strategies will load my standing from Identica utilizing the hAtom microformat. The findContent methodology can solely be used after a search, whereas the load content material works independently of the search.
ident.findContent( 'identi.ca', 'Standing', 'hAtom' );
ident.loadContent( 'http://identi.ca/glennjones', 'identi.ca', 'Identica', 'Standing', 'hAtom' );
The returned knowledge is saved in seven collections: Id, Profile, Resume, Entry, Occasion, XFN, and Tag. As with profiles, an occasion fires to inform you new content material has been added, as soon as it’s collected from the APIs.
You’ll be able to obtain the supply code, together with documentation and examples, from http://identengine.com/. It’s below an MIT open supply licence.
Uncover the probabilities#section17
The quantity of information obtainable on the internet is straight tied to social developments in openness and self publishing. With billions of microformats embedded within the internet and RDF rising in power, it’s now potential to construct purposes on this knowledge. Now it’s your flip to make use of id discovery to construct a bit magic into the consumer experiences you design.