
In our earlier article we described how the browser makes use of CSS to render stunning pixels to the consumer’s display screen. Though fashionable CSS can (and may!) be used to create extremely interactive consumer experiences, for the final mile of interactivity, we have to dynamically replace the HTML doc. For that, we’re going to wish JavaScript.
Article Continues Beneath
For a contemporary internet software, the JavaScript that the browser first sees will usually not be the JavaScript written by a developer. As an alternative, it would almost definitely be a bundle produced by a software reminiscent of webpack. And it’ll most likely be a slightly giant bundle containing a UI framework reminiscent of React, numerous polyfills (libraries that emulate new platform options in older browsers), and an assortment of different packages discovered on npm. The primary problem for the browser’s JavaScript engine is to transform that huge bundle of textual content into directions that may be executed on a digital machine. It must parse the code, and since the consumer is ready on JavaScript for all that interactivity, it must do it quick.
At a excessive degree, the JavaScript engine parses code identical to some other programming language compiler. First, the stream of enter textual content is damaged up into chunks known as tokens. Every token represents a significant unit throughout the syntactic construction of the language, just like phrases and punctuation in pure written language. These tokens are then fed right into a top-down parser that produces a tree construction representing this system. Language designers and compiler engineers wish to name this tree construction an AST (summary syntax tree). The ensuing AST can then be analyzed to supply a listing of digital machine directions known as bytecode.
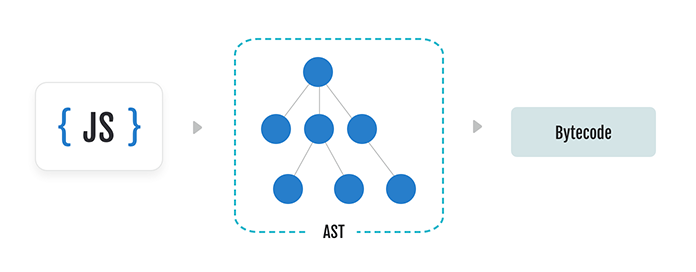
The method of producing an AST is among the extra simple features of a JavaScript engine. Sadly, it can be sluggish. Do not forget that huge bundle of code we began out with? The JavaScript engine has to parse and construct syntax timber for all the bundle earlier than the consumer can begin interacting with the location. A lot of that code could also be pointless for the preliminary web page load, and a few could not even be executed in any respect!
Fortuitously, our compiler engineers have invented quite a lot of methods to hurry issues up. First, some engines parse code on a background thread, releasing up the principle UI thread for different computations. Second, fashionable engines will delay the creation of in-memory syntax timber for so long as attainable through the use of a way known as deferred parsing or lazy compilation. It really works like this: if the engine sees a operate definition which may not be executed for some time, it would carry out a quick, “throwaway” parse of the operate physique. This throwaway parse will discover any syntax errors that is perhaps lurking throughout the code, nevertheless it is not going to generate an AST. Later, when the operate is known as for the primary time, the code might be parsed once more. This time, the engine will generate the complete AST and bytecode required for execution. On the planet of JavaScript, doing issues twice can generally be quicker than doing issues as soon as!
The very best optimizations, although, are those that permit us to bypass doing any work in any respect. Within the case of JavaScript compilation, this implies skipping the parsing step fully. Some JavaScript engines will try and cache the generated bytecode for later reuse in case the consumer visits the location once more. This isn’t fairly so simple as it sounds. JavaScript bundles can change steadily as web sites are up to date, and the browser should rigorously weigh the price of serializing bytecode in opposition to the efficiency enhancements that come from caching.
Bytecode to runtime#section3
Now that we’ve our bytecode, we’re prepared to start out execution. In at the moment’s JavaScript engines, the bytecode that we generated throughout parsing is first fed right into a digital machine known as an interpreter. An interpreter is a bit like a CPU carried out in software program. It seems at every bytecode instruction, one after the other, and decides what precise machine directions to execute and what to do subsequent.
The construction and habits of the JavaScript programming language is outlined in a doc formally often called ECMA-262. Language designers wish to name the construction half “syntax” and the habits half “semantics.” The semantics of virtually each side of the language is outlined by algorithms which can be written utilizing prose-like pseudo-code. As an illustration, let’s faux we’re compiler engineers implementing the signed proper shift operator (>>). Right here’s what the specification tells us:
ShiftExpression : ShiftExpression >> AdditiveExpression
- Let lref be the results of evaluating ShiftExpression.
- Let lval be ? GetValue(lref).
- Let rref be the results of evaluating AdditiveExpression.
- Let rval be ? GetValue(rref).
- Let lnum be ? ToInt32(lval).
- Let rnum be ? ToUint32(rval).
- Let shiftCount be the results of masking out all however the least vital 5 bits of rnum, that’s, compute rnum & 0x1F.
- Return the results of performing a sign-extending proper shift of lnum by shiftCount bits. Probably the most vital bit is propagated. The result’s a signed 32-bit integer.
Within the first six steps we convert the operands (the values on both facet of the >>) into 32-bit integers, after which we carry out the precise shift operation. For those who squint, it seems a bit like a recipe. For those who actually squint, you would possibly see the beginnings of a syntax-directed interpreter.
Sadly, if we carried out the algorithms precisely as they’re described within the specification, we’d find yourself with a really sluggish interpreter. Think about the straightforward operation of getting a property worth from a JavaScript object.
Objects in JavaScript are conceptually like dictionaries. Every property is keyed by a string title. Objects also can have a prototype object.
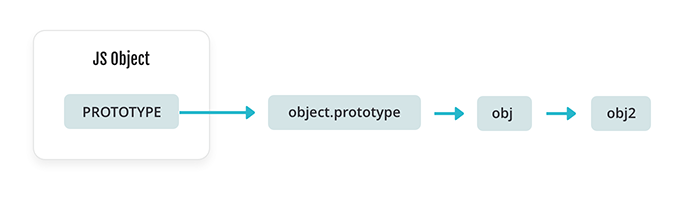
If an object doesn’t have an entry for a given string key, then we have to search for that key within the prototype. We repeat this operation till we both discover the important thing that we’re in search of or get to the tip of the prototype chain.
That’s probably loads of work to carry out each time we wish to get a property worth out of an object!
The technique utilized in JavaScript engines for rushing up dynamic property lookup is known as inline caching. Inline caching was first developed for the language Smalltalk within the Eighties. The fundamental concept is that the outcomes from earlier property lookup operations will be saved straight within the generated bytecode directions.
To see how this works, let’s think about that the JavaScript engine is a towering gothic cathedral. As we step inside, we discover that the engine is chock filled with objects swarming round. Every object has an identifiable form that determines the place its properties are saved.
Now, think about that we’re following a collection of bytecode directions written on a scroll. The following instruction tells us to get the worth of the property named “x” from some object. You seize that object, flip it over in your fingers a couple of instances to determine the place “x” is saved, and discover out that it’s saved within the object’s second knowledge slot.
It happens to you that any object with this identical form could have an “x” property in its second knowledge slot. You pull out your quill and make an observation in your bytecode scroll indicating the form of the item and the placement of the “x” property. The following time you see this instruction you’ll merely examine the form of the item. If the form matches what you’ve recorded in your bytecode notes, you’ll know precisely the place the information is positioned with out having to examine the item. You’ve simply carried out what’s often called a monomorphic inline cache!
However what occurs if the form of the item doesn’t match our bytecode notes? We are able to get round this downside by drawing a small desk with a row for every form we’ve seen. Once we see a brand new form, we use our quill so as to add a brand new row to the desk. We now have a polymorphic inline cache. It’s not fairly as quick because the monomorphic cache, and it takes up a little bit extra space on the scroll, but when there aren’t too many rows, it really works fairly properly.
If we find yourself with a desk that’s too huge, we’ll wish to erase the desk, and make an observation to remind ourselves to not fear about inline caching for this instruction. In compiler phrases, we’ve a megamorphic callsite.
Usually, monomorphic code may be very quick, polymorphic code is sort of as quick, and megamorphic code tends to be slightly sluggish. Or, in haiku kind:
A number of shapes, leaping fox
Many shapes, turtle
Interpreter to just-in-time (JIT)#section4
The wonderful thing about an interpreter is that it might begin executing code rapidly, and for code that’s run solely a few times, this “software program CPU” performs acceptably quick. However for “nóng code” (capabilities which can be run tons of, hundreds, or hundreds of thousands of instances) what we actually need is to execute machine directions straight on the precise {hardware}. We wish just-in-time (JIT) compilation.
As JavaScript capabilities are executed by the interpreter, numerous statistics are gathered about how usually the operate has been known as and what sorts of arguments it’s known as with. If the operate is run steadily with the identical sorts of arguments, the engine could determine to transform the operate’s bytecode into machine code.
Let’s step as soon as once more into our hypothetical JavaScript engine, the gothic cathedral. As this system executes, you dutifully pull bytecode scrolls from rigorously labeled cabinets. For every operate, there may be roughly one scroll. As you observe the directions on every scroll, you document what number of instances you’ve executed the scroll. You additionally notice the shapes of the objects encountered whereas finishing up the directions. You’re, in impact, a profiling interpreter.
Whenever you open the following scroll of bytecode, you discover that this one is “nóng.” You’ve executed it dozens of instances, and also you assume it could run a lot quicker in machine code. Fortuitously, there are two rooms filled with scribes which can be able to carry out the interpretation for you. The scribes within the first room, a brightly lit open workplace, can translate bytecode into machine code fairly quick. The code that they produce is of excellent high quality and is concise, nevertheless it’s not as environment friendly because it could possibly be. The scribes within the second room, darkish and misty with incense, work extra rigorously and take a bit longer to complete. The code that they produce, nevertheless, is extremely optimized and about as quick as attainable.
In compiler-speak, we refer to those completely different rooms as JIT compilation tiers. Totally different engines have completely different numbers of tiers relying on the tradeoffs they’ve chosen to make.
You determine to ship the bytecode to the primary room of scribes. After engaged on it for a bit, utilizing your rigorously recorded notes, they produce a brand new scroll containing machine directions and place it on the right shelf alongside the unique bytecode model. The following time you have to execute the operate, you need to use this quicker set of directions.
The one downside is that the scribes made fairly a couple of assumptions after they translated our scroll. Maybe they assumed {that a} variable would all the time maintain an integer. What occurs if a kind of assumptions is invalidated?
In that case we should carry out what’s often called a bailout. We pull the unique bytecode scroll from the shelf, and work out which instruction we must always begin executing from. The machine code scroll disappears in a puff of smoke and the method begins once more.
To infinity and past#section5
In the present day’s high-performance JavaScript engines have advanced far past the comparatively easy interpreters that shipped with Netscape Navigator and Web Explorer within the Nineteen Nineties. And that evolution continues. New options are incrementally added to the language. Frequent coding patterns are optimized. WebAssembly is maturing. A richer normal module library is being developed. As builders, we are able to anticipate fashionable JavaScript engines to ship quick and environment friendly execution so long as we hold our bundle sizes in examine and take a look at to ensure our performance-critical code shouldn’t be overly dynamic.
